728x90
통계 분석
describe()
pandas의 DataFrame은 describe이라는 각 컬럼의 평균값, 최대치, 최소치, 편차 등을 알 수 있는 메소드가 있다.
연습을 위해 iris데이터를 불러온다.
from sklearn.datasets import load_iris
iris=load_iris()
처음 불러오면 위와 같이 배열로 되어있기 때문에 DataFram형태로 바꿔준다.
# feature_names 와 target을 레코드로 갖는 데이터프레임 생성
iris_df = pd.DataFrame(data=iris.data, columns=iris.feature_names)
iris_df['target'] = iris.target
# 0.0, 1.0, 2.0으로 표현된 label을 문자열로 매핑
iris_df['target'] = iris_df['target'].map({0:"setosa", 1:"versicolor", 2:"virginica"}) iris_df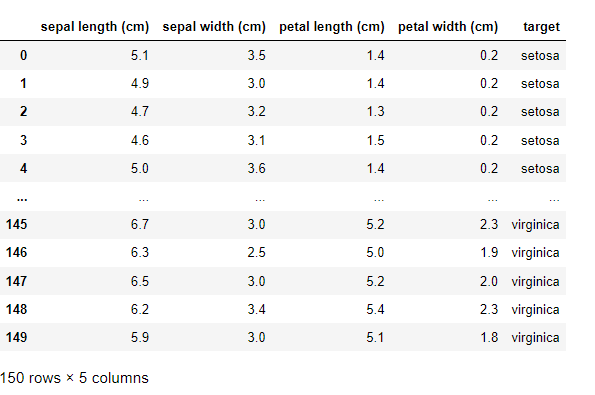
describe를 사용해 통계치를 확인한다.
data_description = iris_df.describe()
data_description
이 통계치를 활용하면 분포를 가늠하기 쉽다!
coloumns = ['sepal length (cm)' , 'sepal width (cm)', 'petal length (cm)','petal width (cm)']
plt.style.use('fivethirtyeight') # 스타일 바꾸기
fig, ax =plt.subplots(2,2, figsize = (10, 10))
fig.suptitle('Histogram of coloumns', fontsize=40)
column_idx = 0
for i in range(2):
for j in range(2):
ax[i][j].hist(iris_df[coloumns[column_idx]], bins=30, color='#eaa18a', edgecolor='#7bcabf')
ax[i][j].set_title(coloumns[column_idx])
#평균
ax[i][j].axvline(data_description[coloumns[column_idx]]['mean'], c='#f55354',
label = f"mean = {round(data_description[coloumns[column_idx]]['mean'], 2)}")
#중앙값
ax[i][j].axvline(data_description[coloumns[column_idx]]['50%'], c='#518d7d',
label = f"median = {round(data_description[coloumns[column_idx]]['50%'], 2)}")
ax[i][j].legend()
column_idx += 1
이렇게 하면 분포와 중앙값, 평균을 함께 확인할 수 있다.
이상치 확인
sns.boxplot()
boxplot 명령은 박스-휘스커 플롯(Box-Whisker Plot) 혹은 간단히 박스 플롯이라 부르는 차트를 그려준다.
- 박스는 실수 값 분포에서 1사분위수(Q1)와 3사분위수(Q3)를 뜻하고 이 3사분위수와 1사분수의 차이(Q3 - Q1)를 IQR(interquartile range)라고 한다.
- 박스 내부의 가로선은 중앙값을 나타낸다.
- 박스 외부의 세로선은 1사분위 수보다 1.5 x IQR 만큼 낮은 값과 3사분위 수보다 1.5 x IQR 만큼 높은 값의 구간을 기준으로 그 구간의 내부에 있는 가장 큰 데이터와 가장 작은 데이터를 잇는 선분이다.
- 그 바깥의 점은 아웃라이어(outlier)라고 부르는데 일일히 점으로 표시한다.
- 아웃라이어(outlier)는 이상치로 판단할 수 있는 값이다.
sns.boxplot(iris_df['sepal width (cm)'])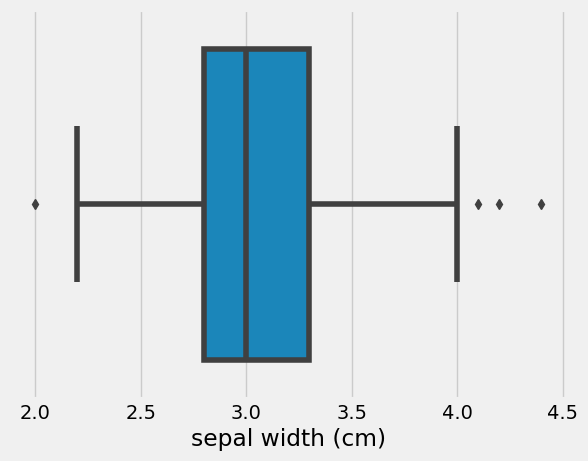
'데이터 이해하기 > 시각화' 카테고리의 다른 글
| plt.style.use() - matplotlib 테마 바꾸기 (0) | 2021.11.04 |
|---|
