2022.03.15 - [프로젝트] - 사무실 내 전력량 예측 (1)
사무실 내 전력량 예측 (1)
2주간 인턴을 하게 된 회사에서 작은 프로젝트를 진행했었다. 주제는 사무실에서 사용되고 있는 전력량을 예측하는 프로젝트! 사무실에서 사용하고있는 전기를 측정해둔 데이터가 있었고 이를
studydaily.tistory.com
결측치 처리하기
그 후, 데이터의 결측치를 확인해 보았다.
train.isna().sum()
가장 중요한,, 종속변수 meterage에 결측치가 있었다,,!
종속변수의 결측치를 어떻게 처리할까 많은 고민을 했다. 어디에서 결측치가 있는지 먼저 확인을 해보았다.
train[train['meterage'].isnull()]
' 왜 저기에 결측치가 있을까? 이 결측치를 어떻게 처리하지? ' 많은 고민을 하였다.
시계열 데이터이기 때문에 1개라도 그냥 삭제해버리면 안 되겠다는 생각을 했다.
그래서 통계값을 확인해 보았다.
train['meterage'].describe()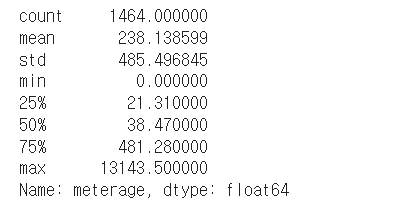
min값이 0이 존재한다??? 0일 수 있을까??
왜 0이 존재하는지 확인해보기 위해 0인 값들만 추출해보았다.
zero=train.loc[train['meterage']==0]
zero
밤에 모든 전기를 껐다면 그럴 수 도 있겠다 생각했는데, 시간과 상관없이 0인 값들이 불규칙하게 존재했다.
담당자님께 여쭤보니 측정기기를 껐다 켰다 하면서 생긴 이상치였다...
그렇다면 이 이상치를 어떻게 처리하면 좋을까?
.
.
.
평일과 주말, 시간대별 평균으로 이 값들을 대체하면 될 것 같았다!
그전에, 0 이외에 더 이상치가 없을까?
plt.plot(train['meterage'])
# Basic box plot
plt.boxplot(train['meterage'])
plt.show()
특정 날짜들에 너무 큰 값이 있는 것을 확인했다.
통계 값에서 max가 13143.500000 였는데, 이 값이 나올 수 없는 전력 사용량이라는 것을 알게 되었다.
그 외에도 4000 이상의 값들은 이상치로 생각되었다.
이렇게 큰 이상치가 있다면 평균값으로 대체할 때 문제가 값에 영향을 미칠 것 같아서 너무 큰 값은 먼저 처리해주어야 할 것 같았다.
그래서 5000 이상의 값들은 평균값으로 먼저 처리해 주었다.
train.loc[(train['meterage']>=5000),'meterage']=train['meterage'].mean()train['meterage'].describe()
그런 다음 생각한 방법으로 이상치들을 대체해보았다.
먼저 평일의 시간대 평균 구하기 위해 평일 데이터만 추출
weekday=train_df.loc[train_df.is_weekend==1]
weekday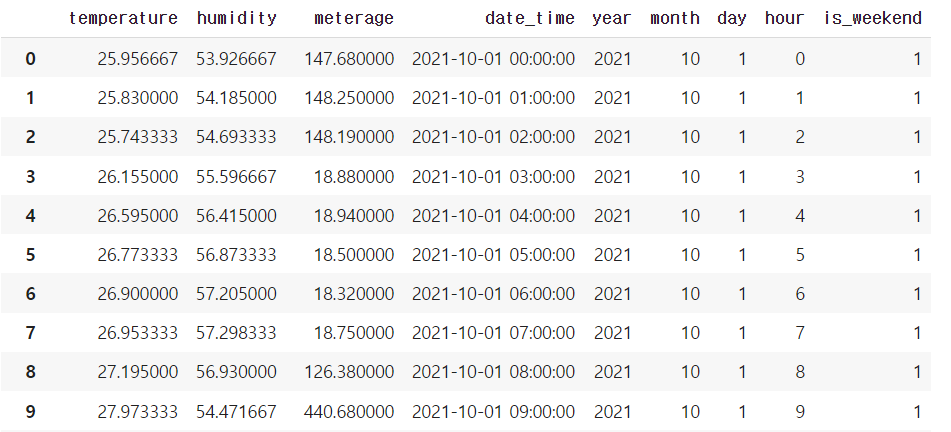
weekday.groupby(['hour'])['meterage'].mean()
주말의 시간대 평균 구하기위해 주말 데이터만 추출
weekend=train_df.loc[train_df.is_weekend==0]
weekend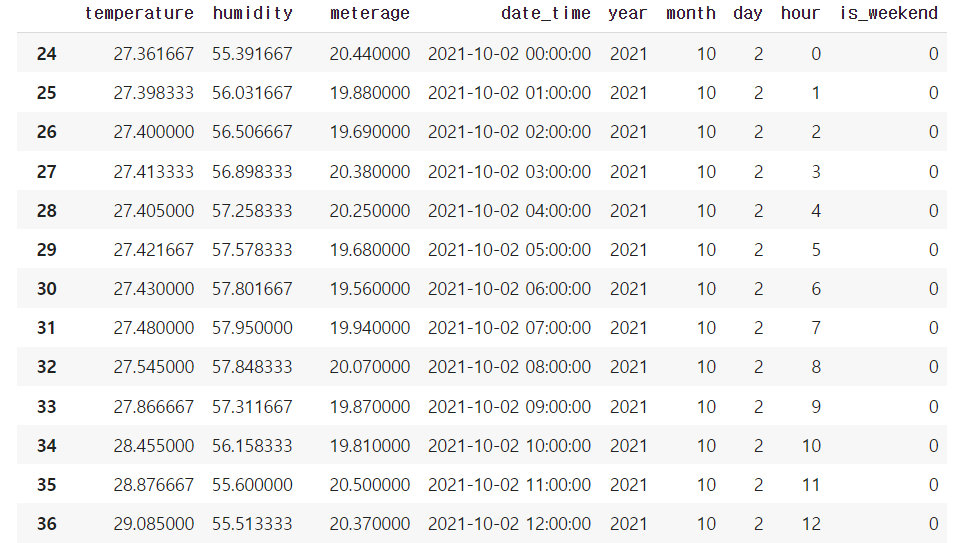
weekend.groupby(['hour'])['meterage'].mean()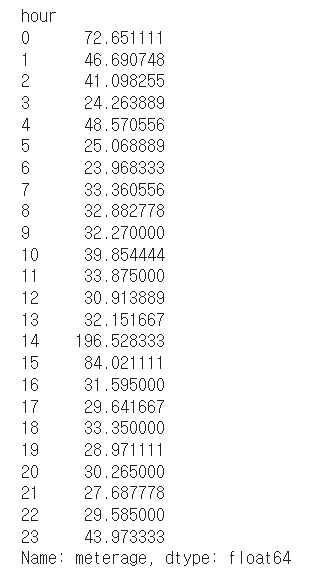
평일의 동시간대 평균으로 대체
for i in range(0,24):
train_df.loc[(train.meterage==0)& (train_df.is_weekend==1) &(train.hour==i),'meterage']=weekday.groupby(['hour'])['meterage'].mean()[i]주말의 동시간대 평균으로 대체
for i in range(0,24):
train_df.loc[(train.meterage==0)& (train_df.is_weekend==0) &(train.hour==i),'meterage']=weekend.groupby(['hour'])['meterage'].mean()[i]
그래프로 확인해보기
month_e = train_df.groupby('month').sum()['meterage']
day_e = train_df.groupby('day').sum()['meterage']
hour_e = train_df.groupby('hour').sum()['meterage']
fig, ax = plt.subplots(1, 3, figsize=(20, 10))
fig.suptitle('avg with time scale', fontsize=30)
# 월별 대여량
ax[0].bar(x=['10', '11'], height=month_e)
ax[0].set_title('month', fontsize = 20)
# 일별 대여량
ax[1].bar(x=day_e.index.to_list(), height= day_e)
ax[1].set_title('day', fontsize = 20)
# 일별 대여량
ax[2].bar(x=hour_e.index.to_list(), height=hour_e)
ax[2].set_title('hour', fontsize = 20)
plt.show()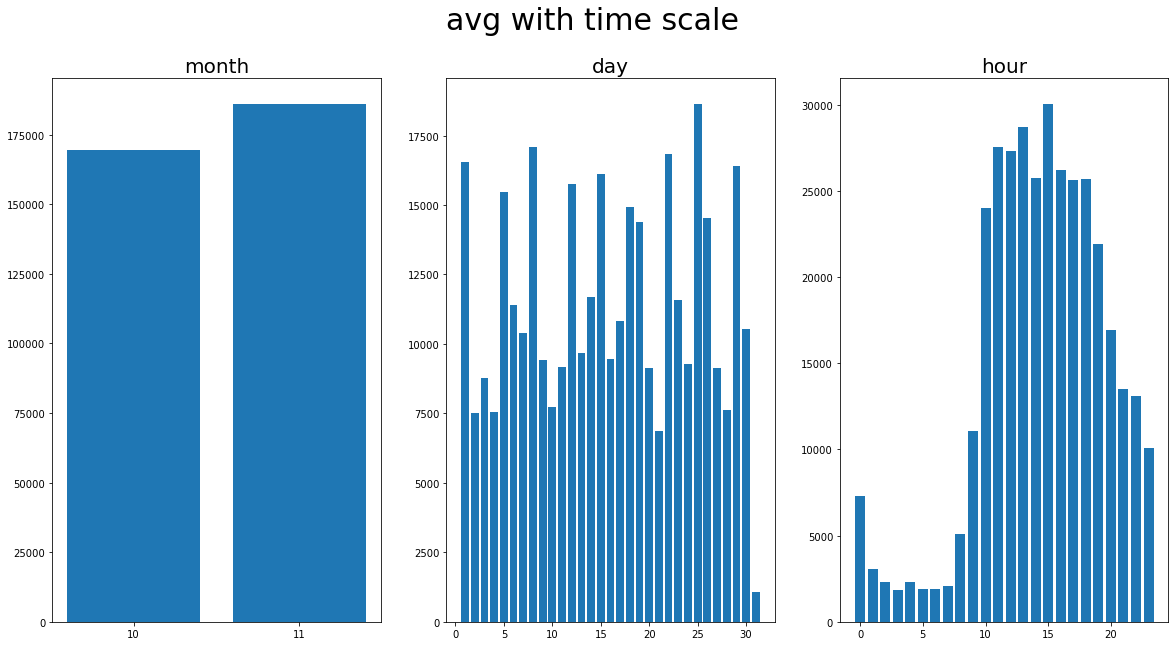
'프로젝트' 카테고리의 다른 글
| 사무실 내 전력량 예측 - (4) (0) | 2022.07.12 |
|---|---|
| 사무실 내 전력량 예측 - (3) (0) | 2022.07.12 |
| 사무실 내 전력량 예측 (1) (1) | 2022.03.15 |
| 따릉이 대여량 예측-(1) (0) | 2021.11.23 |



