728x90
2022.07.12 - [프로젝트] - 사무실 내 전력량 예측 - (3)
사무실 내 전력량 예측 - (3)
2022.03.24 - [프로젝트] - 사무실 내 전력량 예측 - (2) 사무실 내 전력량 예측 - (2) 2022.03.15 - [프로젝트] - 사무실 내 전력량 예측 (1) 사무실 내 전력량 예측 (1) 2주간 인턴을 하게 된 회사에서 작은 프
studydaily.tistory.com
드디어 분석에 들어간다!
학습을 시키기 위해 Train, Test dataset을 설정한다.
시계열 데이터를 어떻게 하면 잘 나눌 수 있을까 많은 고민을 했지만, 결국 가장 단순한 방법으로 시도해 보았다.
sktime library으로 마지막 일주일을 validation set으로 설정
y = data.meterage
x = data.iloc[:,:10]
y_train, y_valid, x_train, x_valid = temporal_train_test_split(y = y, X = x, test_size = 168) # 24시간*7일 = 168
print('train data shape\nx:{}, y:{}'.format(x_train.shape, y_train.shape))
plot_series(y_train, y_valid, markers=[',' , ','])
plt.show()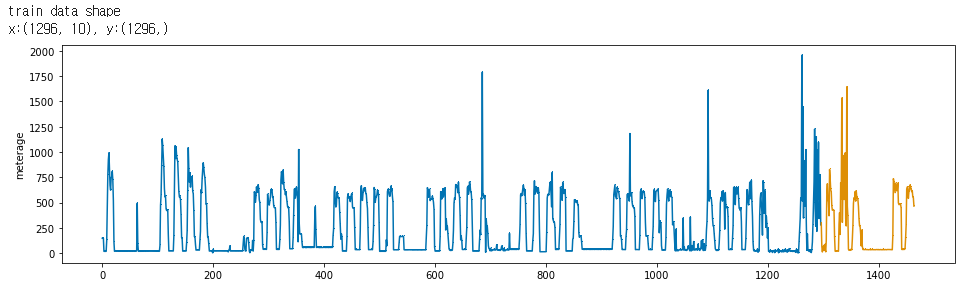
※ 파란색이 Train, 노란색이 Test
성능평가 (SMAPE)
- 일반 mse를 objective function으로 훈련할 때 과소추정
- SMAPE는 전력사용량을 높게 예측하는 것보다 작게 예측할 때 실제로 더 큰 문제가 될 수 있음을 반영한다.
# Define SMAPE loss function
def SMAPE(true, pred):
return np.mean((np.abs(true-pred))/(np.abs(true) + np.abs(pred))) * 100
gridsearchCV
모델 XGBoost를 사용하기위해 최적의 하이퍼 파라미터를 찾아보았다.
파라미터를 찾는 과정은 아래의 블로그를 참조하였다.
https://blog.naver.com/chunsa0127/222427763833
## gridsearchCV for best model : 대략 1시간 소요
from sklearn.model_selection import PredefinedSplit, GridSearchCV
df = pd.DataFrame(columns = ['n_estimators', 'eta', 'min_child_weight','max_depth', 'colsample_bytree', 'subsample'])
preds = np.array([])
grid = {'n_estimators' : [100], 'eta' : [0.01], 'min_child_weight' : np.arange(1, 8, 1),
'max_depth' : np.arange(3,9,1) , 'colsample_bytree' :np.arange(0.8, 1.0, 0.1),
'subsample' :np.arange(0.8, 1.0, 0.1)} # fix the n_estimators & eta(learning rate)
for i in tqdm(np.arange(1, 61)):
y = train_f.loc[train.num == i, 'meterage']
x = train_f.loc[train.num == i, ].iloc[:,:10]
y_train, y_test, x_train, x_test = temporal_train_test_split(y = y, X = x, test_size = 168)
pds = PredefinedSplit(np.append(-np.ones(len(x)-168), np.zeros(168)))
gcv = GridSearchCV(estimator = XGBRegressor(seed = 0, gpu_id = 1,
tree_method = 'gpu_hist', predictor= 'gpu_predictor'),
param_grid = grid, scoring = smape, cv = pds, refit = True, verbose = True)
gcv.fit(x_train, y_train)
best = gcv.best_estimator_
params = gcv.best_params_
print(params)
pred = best.predict(x_test)
building = 'building'+str(i)
print(building + '|| SMAPE : {}'.format(SMAPE(y_test, pred)))
preds = np.append(preds, pred)
df = pd.concat([df, pd.DataFrame(params, index = [0])], axis = 0)
df.to_csv('./hyperparameter_xgb.csv', index = False) # save the tuned parametersxgb_params = pd.read_csv('./data/hyperparameter_xgb.csv')
xgb_reg = XGBRegressor(n_estimators = 10000, eta = xgb_params.iloc[47,1], min_child_weight = xgb_params.iloc[47,2],
max_depth = xgb_params.iloc[47,3], colsample_bytree = xgb_params.iloc[47,4],
subsample = xgb_params.iloc[47,5], seed=0)
# ## 추가
# xgb_reg.set_params(**{'objective':weighted_mse(100), 'metrics':'mse'})
xgb_reg.fit(x_train, y_train, eval_set=[(x_train, y_train), (x_valid, y_valid)],
early_stopping_rounds=300,
verbose=False)
결과 확인
pred = xgb_reg.predict(x_valid)
pred = pd.Series(pred)
pred.index = np.arange(y_valid.index[0], y_valid.index[-1]+1)
plot_series( y_valid, pd.Series(pred), markers=[ ',', ','])
print('best iterations: {}'.format(xgb_reg.best_iteration))
print('SMAPE : {}'.format(SMAPE(y_valid, pred)))best iterations: 329 SMAPE : 18.260381617460414
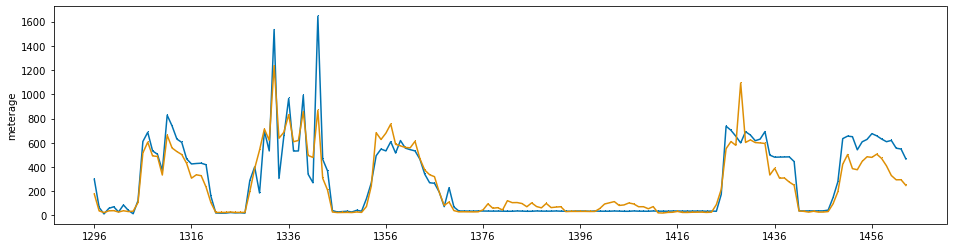
생각보다 성능이 잘 나온것 같아서 매우 뿌듯한 프로젝트였다.
'프로젝트' 카테고리의 다른 글
| 사무실 내 전력량 예측 - (3) (0) | 2022.07.12 |
|---|---|
| 사무실 내 전력량 예측 - (2) (0) | 2022.03.24 |
| 사무실 내 전력량 예측 (1) (1) | 2022.03.15 |
| 따릉이 대여량 예측-(1) (0) | 2021.11.23 |



