18. 강화학습 (Reinforcement Learning)
18.1 보상을 최적화하기 위한 학습
강화학습에서 소프트웨어 에이전트(agent)는 관측(observation)을 하고 주어진 환경(environment)에서 행동(action)한다. 그리고 그 결과로 보상(reward)을 받는다.
에이전트의 목적은 보상의 장기간(long-term) 기대치를 최대로 만드는 행동을 학습하는 것이다.

즉, 에이전트는 환경 안에서 행동하고 시행착오를 통해 보상이 최대가 되도록 학습한다.
이러한 강화학습의 정의는 다음과 같이 다양한 문제에 적용할 수 있다.

- a : 보행 로봇(walking robot)에서는 에이전트(agent)는 보행 로봇을 제어하는 프로그램일 수 있다. 이때 환경(environment)은 실제 세상이고, 에이전트는 카메라나 센서등을 통해 환경을 관찰(observation)한다. 그런 다음 걷는 행동(action)을 한다. 엥전트는 목적지에 도착할 때 양수(positive) 보상을 받고, 잘못된 곳으로 가거나 넘어질 때 음수(negative) 보상(페널티)을 받는다.
- b : 팩맨(pac-man)이라는 게임에서는 에이전트는 팩맨을 제어하는 프로그램이다. 환경은 게임상의 공간이고, 행동은 조이스틱의 방향이 된다. 관측은 스크린숏이 되고 보상은 게임의 점수이다.
18.2 정책 탐색 (Policy Search)
정책이란?
에이전트(agent)가 행동(action)을 결정하기 위해 사용하는 알고리즘 이다.
예를 들어 관측(observation)을 입력으로 받고 행동(action)을 출력하는 신경망이 정책이 될 수 있다.

예를 들어 30분 동안 수집한 먼지의 양을 보상으로 받는 로봇 청소기가 있다고 하자. 이 청소기의 정책은 매 초마다 어떤 확률 p 만큼 전진할 수도 있고, 또는 (1-p)의 확률로 랜덤 하게 -r과 +r사이에서 회전하는 것일 수도 있다.
이 정책에는 무작위성이 포함되어 있으므로 확률적 정책(stochastic policy)라고 한다.
정책 탐색
이러한 정책을 가지고 '30분 동안 얼마나 많은 먼지를 수집할 것인가'에 대한 문제를 해결하기 위해 어떻게 로봇 청소기를 훈련(training) 시킬 수 있을까?

로봇 청소기 예제에는 변경이 가능한 두 개의 정책 파라미터(policy parameter)가 있는데, 확률 p와 각도의 범위 r이다.
p 와 r 은 다양한 조합이 될 수 있는데 이처럼 정책 파라미터의 범위를 정책 공간(policy space)라고 하며, 정책 공간에서 가장 성능이 좋은 파라미터를 찾는 것을 정책 탐색(policy search)라고 한다.
정책 탐색에는 다음과 같은 방법들이 있다.
- 단순한(naive) 방법 : 다양한 파라미터 값들로 실험한 뒤 가장 성능이 좋은 파라미터를 선택한다.
- 유전 알고리즘(genetic algorithm) : 기존의 정책(부모)에서 더 좋은 정책(자식)을 만들어 내는 과정(진화)을 통해서 좋은 정책을 찾을 때까지 반복하는 방법이다.
예) 1세대 정책 100개를 랜덤하게 생성 후 낮은 정책 80개 버리고 20개 살려 각각 자식 정책 4개 생성 (2세대)
- 정책 그래디언트(PG, policy gradient) : 정책 파라미터에 대한 보상(reward)의 그래디언트(gradient)를 평가해서 높은 보상의 방향을 따르는 그래디언트로(gradient ascent) 파라미터를 업데이트하는 최적화 방법이다.
18.3 OpenAI 짐
강화학습에서 중요한 요소 중 하나는 에이전트(agent)를 훈련시키기 위한 시뮬레이션 환경이 필요하다.
OpenAI Gym은 다양한 종류의 시뮬레이션 환경(아타리 게임, 보드 게임, 물리 시뮬레이션 등)을 제공하는 툴킷이며, 이를 이용하여 에이전트를 훈련시키고 RL 알고리즘을 개발할 수 있다.
import gym
env = gym.make("CartPole-v0")
obs = env.reset()
img = render_cart_pole(env, obs)
print('obs.shape :', obs.shape)
print('obs :', obs)
print('img.shape :', img.shape)
plot_cart_pole(env, obs)
- make() 함수는 환경(env)을 만든다.
- 환경을 만든 후 reset() 메서드를 사용해 꼭 초기화 해줘야 하는데, 이 함수는 첫 번째 관측(obs)을 리턴한다. 위의 출력 결과에서도 확인할 수 있듯이 CartPole 환경에서의 관측은 길이가 4인 NumPy배열이다.
- obs = [카트의 수평 위치, 속도, 막대의 각도, 각속도]
- render() 메서드는 jupyter notebook이나 별도의 창에 위의 그림과 같이 환경을 출력해준다.
print('env.action_space :', env.action_space)>> env.action_space : Discrete(2)
Discrete(2)는 가능한 행동이 0(왼쪽)과 1(오른쪽)이라는 것을 의미한다.
action = 1 # 오른쪽으로 가속
obs, reward, done, info = env.step(action)
print('obs :', obs)
print('reward :', reward)
print('done :', done)
print('info :', info)
step() 메서드는 주어진 행동을 실행하고 obs, reward, done, info 4개의 값을 리턴한다.
- obs : 새로운 관측값
- reward : 행동에 대한 보상을 말하며, 여기서는 매 스텝마다 1의 보상을 받는다.
- done : 값이 True 이면, 에피소드(게임 한판)가 끝난 것을 말한다. 여기서는 막대가 넘어진 경우를 말한다.
- info : 추가적인 디버깅 정보가 딕셔너리 형태로 저장된다. 여기서는 별도의 정보가 따로 없다.
간단한 정책(policy)을 하드코딩해보도록 하자. 이 정책은 막대가 기울어지는 방향과 반대로 가속시키며, 아래의 코드처럼 500번의 실행해서 얻은 평균 보상을 확인하는 코드이다.
def basic_policy(obs):
angle = obs[2]
return 0 if angle <0 else 1
frames, totals = [], []
for episode in range(500):
episode_rewards = 0
obs = env.reset()
for step in range(200): # 최대 스텝을 200번으로 설정
img = render_cart_pole(env, obs)
frames.append(img)
action = basic_policy(obs)
obs, reward, done, info = env.step(action)
episode_rewards += reward
if done:
break
totals.append(episode_rewards)
결과 확인
import numpy as np
print('totals mean :', np.mean(totals))
print('totals std :', np.std(totals))
print('totals min :', np.min(totals))
print('totals max :', np.max(totals))totals mean : 41.718
totals std : 8.858356280936096
totals min : 24.0
totals max : 68.0
500번을 시도해도 이정 책은 막대를 쓰러뜨리지 않고 68번보다 많은 스텝을 진행하지 못했다.
16.4 신경망 정책
이번에는 위의 CartPole 예제에서 정책(policy)에 신경망(neural networks)을 적용해 보도록 하자.
이 신경망은
1. 관측(obs)을 입력으로 받고
2. 실행할 행동(action)에 대한 확률을 출력한다.
3. 출력된 확률에 따라 랜덤 하게 행동을 선택하여 수행한다.

이처럼 가장 높은 점수의 행동을 바로 선택하지 않고 신경망이 출력한 확률을 랜덤 하게 행동을 선택하는 이유는, 에이전트(agent)가 새로운 행동을 탐험(exploring) 하는 것과 잘할 수 있는 행동을 활용(exploiting)하는 것 사이에 균형이 잘 맞게끔 하기 위해서다.
예시
어떤 음식점에 처음 방문했다고 하자.
모든 메뉴가 좋아 보여서 아무거나 골랐는데, 이 음식이 맛있었다면 다음에 다시 이 메뉴를 주문할 가능성이 높을 것이다. 하지만, 이 확률이 100%가 되어서는 안 되는데 그 이유는 다른 더 맛있는 메뉴를 전혀 시도해보지 않을 것이기 때문에, 이를 방지하기 위해 확률을 100%라고 설정하지 않는다.
다음의 예제 코드는 텐서 플로(Tensor Flow)를 이용하여 CartPole 환경에 대해 신경망 정책을 구현한 코드이다.
import tensorflow as tf
from tensorflow import keras
n_inputs = 4 # == env.observation_space.shape[0]
model = keras.models.Sequential([
keras.layers.Dense(5, actuvation ="elu", input_shape=[n_inputs]),
keras.layers.Dense(1, actuvation ="sigmoid"),
])
지금까지는 관측을 받아 행동을 출력하는 신경망 정책을 만들었다.
하지만 어떻게 훈련을 시켜야 할까?
18.5 행동 평가 : 신용 할당 문제
만약, 각 스텝마다 가장 좋은 행동이 무엇인지 알고 있다면, 신경망이 예측(출력)한 확률과 타깃 확률 사이의 교차 엔트로피(cross entropy)를 최소화하도록 신경망을 훈련시킬 수 있다. (이는 일반적인 지도 학습과 같다.)
하지만, 대부분의 강화 학습에서는 에이전트가 얻을 수 있는 것은 행동에 대한 보상(reward)뿐이다.
일반적으로 보상은 드물고 지연되어 나타나는데,
예를 들어 CartPole에서 에이전트가 100 스텝 동안 막대의 균형을 유지했을 경우, 100번의 행동(action) 중에 어떤 것이 좋고/나쁜지를 알지 못한다. 다만 알 수 있는 것은 막대가 마지막 행동 뒤에 쓰러졌다는 것만 알 수 있다.
하지만, 마지막 행동 때문에 막대가 쓰러졌다고는 볼 수 없는데
이러한 것을 신용 할당 문제(credit assignment problem)라고 한다. 즉, 에이전트가 보상을 받았을 때 어떤 행동 때문에 받았는지 알기 어렵다.
해결법
행동이 일어난 후 각 단계마다 할인 계수(discount factor) γ(감마)를 적용한 보상을 모두 합하여 행동을 평가하는 것이다.
할인 계수의 역할은 다음과 같다.
- 할인 계수 γ(감마)가 0에 가까우면 미래의 보상은 현재의 보상보다는 중요하게 취급되지 않는다.
- 1에 가까우면 미래의 보상이 현재의 보상만큼 중요하게 고려된다.
- 일반적으로 할인 계수는 0.95 ~ 0.99이다. γ= 0.95 이면, 13 스텝만큼의 미래서 받는 보상은 당장 받는 보상에 비해 약 절반 정도의 가치가 된다

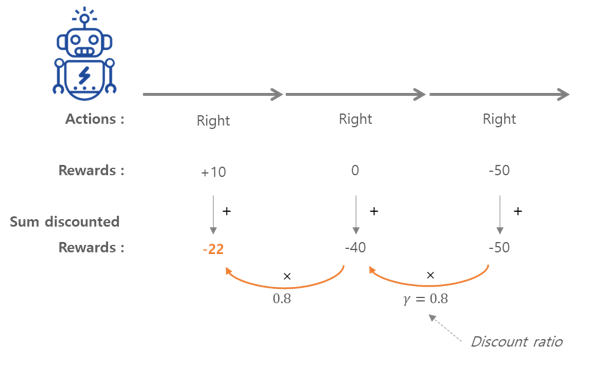
위의 그림에서 처럼 에이전트가 오른쪽으로 3번 이동하기로 결정했을 경우, 첫 번째 스텝에서 +10, 두 번째 스텝에서 0, 세 번째 스텝에서 -50의 보상을 받는다고 할 때, 할인 계수 γ=0.8을 적용하게 되면 첫 번째 행동의 전체 보상은 10+γ X 0 + γ^2 X (-50) = -22가 된다.
좋은 행동 뒤에 나쁜 행동이 계속되면 금방 막대가 넘어져 좋은 행동이 낮은 보상을 받는다.
하지만 충분히 많은 횟수만큼 반복하면 평균적으로 좋은 행동이 나쁜 행동보다 더 높은 보상을 받는다.
-> 많은 에피소드를 실행하고 모든 행동의 대가를 정규화 필요하다.
참고
'스터디 > 딥러닝' 카테고리의 다른 글
| 핸즈온 머신러닝(Hands-On Machine Learning) 18장 - 강화학습(3) (0) | 2021.10.31 |
|---|---|
| 핸즈온 머신러닝(Hands-On Machine Learning) 18장 - 강화학습(2) (0) | 2021.10.30 |
| 핸즈온 머신러닝(Hands-On Machine Learning) 10장 - 케라스를 사용한 인공 신경망 (2)-1 (0) | 2021.10.27 |
| 핸즈온 머신러닝(Hands-On Machine Learning) 10장 - 케라스를 사용한 인공 신경망 (1) (0) | 2021.10.25 |
| 핸즈온 머신러닝 2판 스터디 (딥러닝 파트) (0) | 2021.10.25 |



